Jeśli analizujesz widoczność strony w Google, to nie pomijaj danych z Google Search Console. W GSC Sprawdzisz, jakie frazy spowodowały przekierowanie na stronę, ile wynosi ruch z SERP-ów (Search Engine Results Page), skontrolujesz podstawowe wskaźniki internetowe. Mnóstwo cennych danych dostarcza również zakładka Indeksowanie. Zobacz, co tam znajdziesz.
Indeksowanie w Google Search Console
Żeby sprawdzić dane dotyczące strony w GSC, musisz najpierw zweryfikować witrynę. Później zaczną się pojawiać informacje związane z widoczności serwisu w Google. Zaloguj się do GSC pod adresem https://search.google.com. Po lewej znajdziesz menu, a tam opcję Indeksowanie. Zweryfikujmy poszczególne pozycje.
Strony
W tej zakładce znajdziesz najwięcej danych. Na górze są informacje o indeksacji stron. Na zielono podświetlona jest liczba podstron, które znajdują się w indeksie wyszukiwarki, a obok – URL-e, których z pewnych względów nie ma w Google. Dlaczego? Tego dowiesz się z danych, które są pod wykresem.
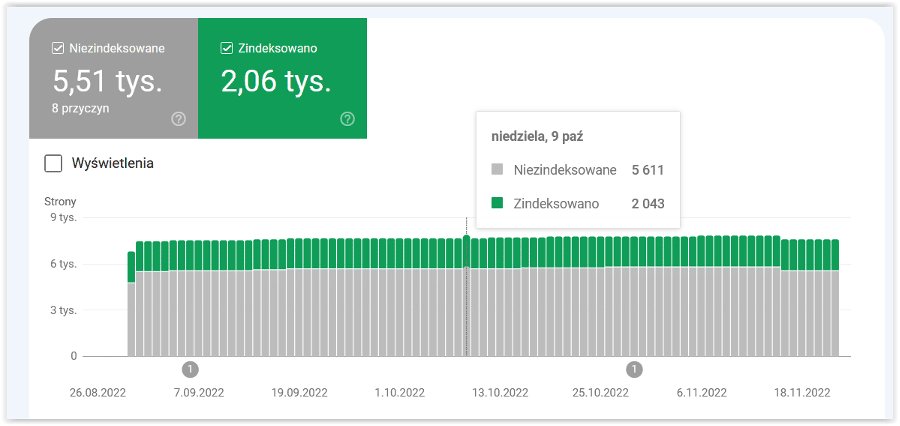
Znajdziesz tam listę przyczyn braku indeksacji, a po kliknięciu każdej pozycji dowiesz się, w przypadku jakich adresów URL wykryto problem. Zwróć uwagę na kolumnę Źródło. Jeśli jest nim strona internetowa, to sam napraw błąd. W przypadku gdy źródłem są Systemy Google, to przeszkoda nie leży po stronie witryny.
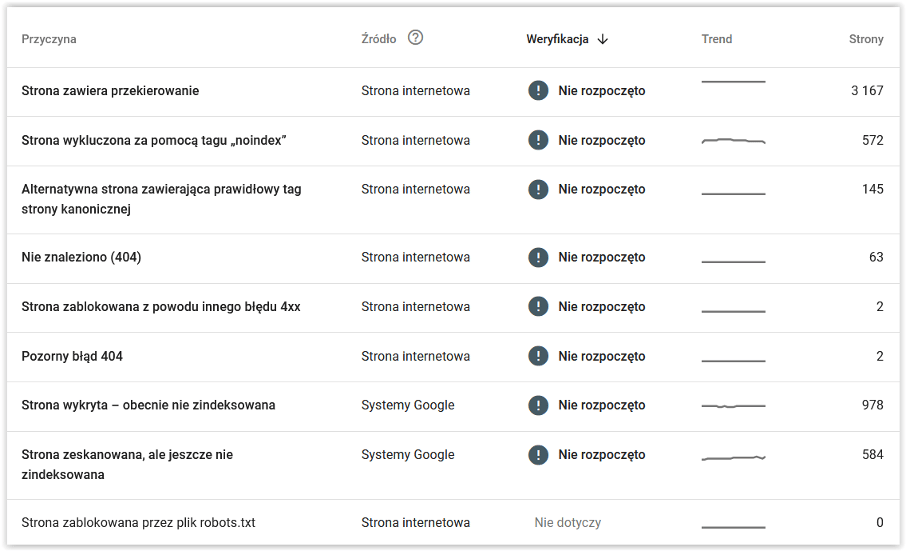
Jeżeli Google w Search Console pokazuje, że coś nie indeksuje się nie oznacza to do razu błędu oraz nie powinno powodować ataku paniki. Informacje o adresach URL, które nie sa indeksowane nierzadko są naszym celowym działaniem i po rpostu Google o tym nas informuje.
Przykładowo, jeżeli wykonaliśmy jakieś przekierowanie ze strony nieistniejącej na nową to taka informacja może pojawić się w zakładce „Strona zawiera przekierowanie” i jest to celowe działanie. Dlatego nie powinniśmy denerwować się i zastanawiać czemu jest to błąd – bo błędem to nie jest.
W przypadku np. WordPressa pojawiają się adresy typu /feed/, które nie są indeksowane z takiego powodu, że są informacją dla czytników typu RSS i nie powinny pojawić się w indeksie.
Warto też pamiętać, że naprawienie jednym błędów z indeksacją może powodować zmniejszenie liczby w jednej pozycji a zwiększenie w drugiej: jeśli strona pojawiała się w zakładce „pozorny błąd 404” a teraz naprawdę generuje błąd 404 to ona przeskoczy z jednego miejsca w drugie.
Każdy wiersz zawiera informacje o próbce danych. To bardzo ważna informacja: próbka danych 1000 wierszy. Tak więc jeśli chcesz obejrzeć dokładniejsze dane musisz mieć mapę serwisu (sitemap.xml) podzieloną na pliczki po 1000 adresów URL i dodane osobno do GSC – wtedy analiza staje się upierdliwa, ale jest dokładniejsza. Przecież mamy aż 500 plików możliwych do dodania.
Jak wspomniałem GSC pokazuje próbki danych i nie musi ich aktualizować adhoc, GSC lubi mieć też opóźnienia w aktualizacji danych rzędu 2-3 dni. Mapy nie są czytane ciągle: większe mogą być aktualizowane co 4-5 dni, mniejsze co 2-3 dni ale zdarzają się tez przestoje kilkutygodniowe.
Strona zawiera przekierowanie
Adres URL przekierowuje do innego adresu URL, dlatego nie został zindeksowany. Końcowy docelowy adres URL może zostać zindeksowany i powinien pojawić się w tym raporcie. Jeśli testujesz ten adres URL, korzystając z raportu narzędzia do sprawdzania adresów URL, test strony zindeksowanej wykaże przekierowanie. Rozpocznie się test wersji opublikowanej, w ramach którego zostanie sprawdzona strona przekierowania, ale adres URL sprawdzanej strony i strony przekierowania będzie niewidoczny.
Oznacza to, że dany adres URL przenosi na inny. W takim przypadku Google nie indeksuje tej strony – w wynikach wyszukiwania może się pojawić adres docelowy. Jeśli masz ustawione w serwisie przekierowanie 301 z podstrony A na B, to w SERP-ach może wyświetlać się strona B.
Przy każdej pozycji na liście problematycznych adresów URL znajdziesz lupkę. Kliknij ją, a wtedy zobaczysz szczegóły dotyczące indeksowania danego materiału.

Analiza przekierowań jest stosunkowo prosta – wchodzimy w dany element i wyrywkowo analizujemy przekierowania. Jeśli są celowo ustawione (przez nas) to taka analiza jest zbędna. Skupiamy się na tych przekierowaniach, które mogą być stare, podejrzane, lub wiemy, iż można się ich pozbyć.
Przekierowania pojawiają się np. po przebudowie serwisu wiec warto zadbać, aby linkowanie wewnętrzne zostało „wyprostowane”.

GSC może pokazywać przekierowania nawet sprzed kilku lat więc jest to celowa informacja, że takie przekierowanie istnieje.
Historycznie proces pozycjonowania powoduje powstawanie zewnętrznych adresów, które kierują do starej struktury – dopóki stare adresy istnieją to próbka i przekierowaniach będzie tutaj się pojawiać. Nic z tym nie zrobicie.
Strona wykluczona za pomocą tagu „noindex”
Za pomocą tagu „noindex” możesz wykluczyć z indeksacji materiały, jeśli nie chcesz, aby znalazły się w wynikach wyszukiwania. Chodzi o kod, który dodaje się w sekcji <head> strony i wygląda następująco:
<meta name=”robots” content=”noindex „>
To oznacza, że robot wyszukiwarki ma nie indeksować tej treści. Noindex może być przesłane również w nagłówki strony, tzn. w pliku .htaccess na serwerze z oprogramowaniem Apache lub w głównym pliku.conf na serwerach Nginx.
Kliknij lupkę obok danego adresu URL, a sprawdzisz szczegóły. Jeśli indeksacja jest zablokowana przypadkiem, to usuń odpowiedzialny za to kod, a potem skorzystaj z pola Sprawdź dowolny URL w… i poproś o zindeksowanie materiału.
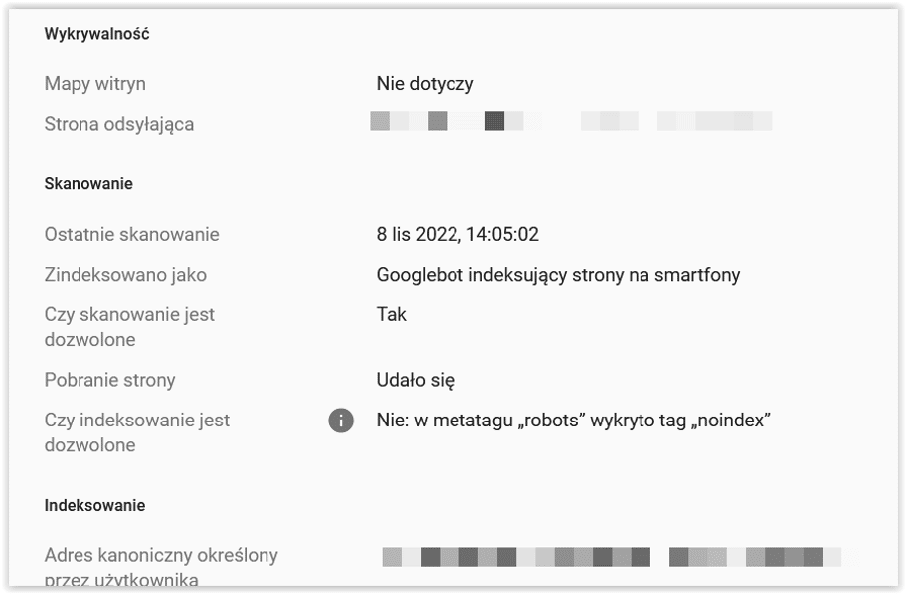
Alternatywna strona zawierająca prawidłowy tag strony kanonicznej
Ta strona jest oznaczona jako alternatywa innej strony (czyli jest to strona AMP z kanoniczną wersją komputerową, mobilna wersja kanonicznej wersji komputerowej lub wersja komputerowa kanonicznej wersji mobilnej). Ta strona prawidłowo wskazuje stronę kanoniczną, która została zindeksowana, więc nie musisz nic robić. Search Console nie wykrywa alternatywnych wersji językowych stron.
Oznacza to, że dana strona jest duplikatem innej i prawidłowo wskazuje na oryginalną wersję za pomocą linka kanonicznego. Nie powinna znaleźć się w indeksie Google. Zindeksowana musi być wersja kanoniczna strony. Zareaguj, jeśli doszło do błędu i link kanoniczny wskazuje na nieodpowiedni adres.
Kliknij przy danym URL-u lupkę, a następnie sprawdź, jaki adres widzisz obok Adres kanoniczny określony przez użytkownika. Czy jest on prawidłowy? Jeśli nie, to napraw błąd.
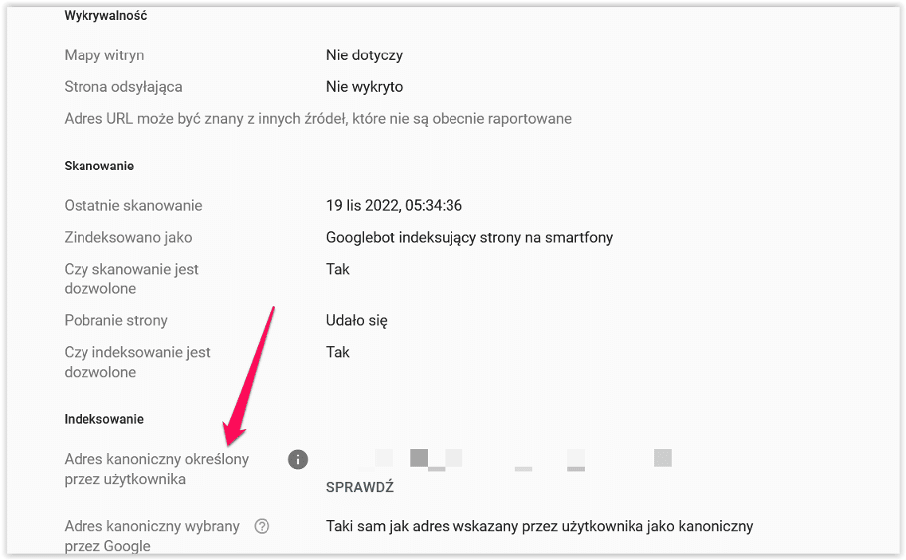
Zwracam uwagę, że ten komunikat jest informacją o prawidłowym tagu canonical. Nie trzeba nic kompletnie robić.

Najczęściej tag kanoniczny prawidłowy jest komunikowany przy adresach URL z parametrami. W sklepach internetowych dotyczy to np. sortowania, filtracji, stronicowania (jeśli canonical wskazuj na pierwszą stronę paginacji).
Jak widać na powyższych screenie pozostałości po dziwnych testach związanych z amp powodują, że te adres nadal są widziane w GSC ale nie istnieją natomiast komunikat o canonical wskazuje, że jest on ustawiony prawidłowo.
Duplikat, wyszukiwarka Google wybrała inną stronę kanoniczną niż użytkownik
Ta strona jest nieoznaczonym duplikatem innej strony. Robot Google wybrał inną stronę jako kanoniczną, więc ta strona nie będzie wyświetlana w wyszukiwarce. Możesz sprawdzić ten adres URL, żeby zobaczyć, który adres URL jest traktowany przez Google jako kanoniczny w przypadku tej strony.
Jeśli uważasz, że robot Google wybrał odpowiednią stronę jako kanoniczną, nie musisz nic więcej robić. Jeśli uważasz, że robot Google wybrał zły adres URL jako kanoniczny, możesz wyraźnie oznaczyć kanoniczny adres URL w przypadku tej strony. Jeśli uważasz, że ta strona nie jest duplikatem strony kanonicznej wybranej przez Google, upewnij się, że jej zawartość znacznie się różni.
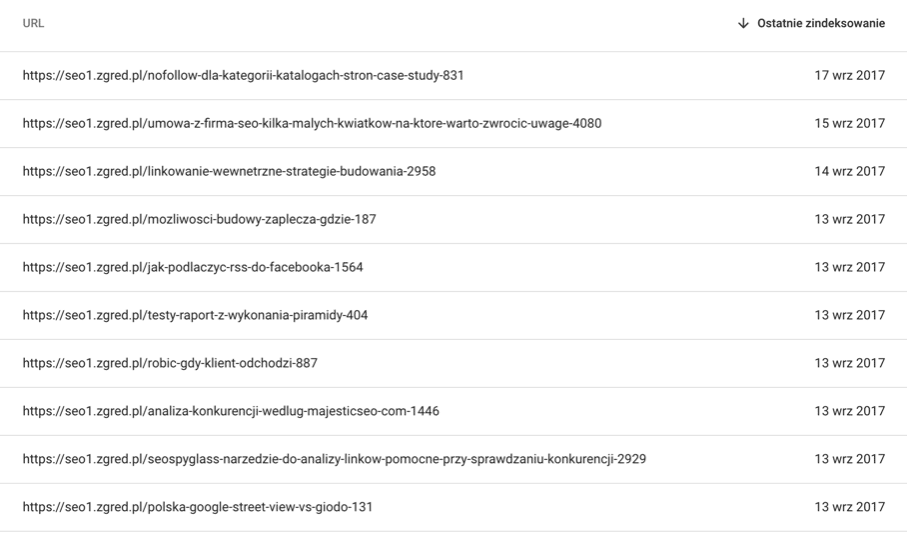
To jest dość ciekawy przypadek i jednocześnie najtrudniejszy do ogarnięcia, ale pokazujący jak dużo, czasem złego, dzieje się w serwisie. W przypadku Zgreda GSC nadal pokazuje adresy URL z roku 2017, które się zaindeksowały. Wtedy Google podjęło samodzielnie decyzję o tym, że canonical nie będzie typu „self” tylko dobierze sobie samodzielnie inne adresy. Wtedy wybrał właściwe pokazując, że pod adresami seo1 są zduplikowane adresy URL i canonical wskazuje adresy bez jedynki.
W przypadku sklepów internetowych w tej zakładce niejednokrotnie będzie ogromny pierdolnik, którego nie da rady się pozbyć. Dlaczego? Ponieważ jeden produkt może być pod wieloma rozmiarami, generując kolejne podstrony różniące się np. szerokością, i wtedy powstaje nam powiedzmy 50 podstron żaluzji materiałowej, różniącej się jedynie rozmiarem (co 1 cm) a opis jedt identyczny.
Nie mamy wtedy wpływu na to, jaki canonical ustawi sobie Google. Jeśli naszym celem był produkt podstawowy z konfiguratorem może się okazać, ze canonical wskazuje żaluzję o szerokości 33 cm.
Na przykład w sklepach z alkoholami mamy kilka kart produktów danego alkoholu różniących się od siebie jedynie „litrażem” – wtedy, pomimo wdrożonego canonical typu „self” Google sam sobie dobiera ten parametr i może ise okazać, że indeksuje litraż typu 200ml a my chcemy indeksować 1-litrowe buteleczki 😉
W takim przypadku pozostaje rozgrzebywanie content, dodawanie opinii lub finalnie – przebudowa karty produktu.
Duplikat, użytkownik nie oznaczył strony kanonicznej
Ta strona jest nieoznaczonym duplikatem innej strony. Robot Google wybrał inną stronę jako kanoniczną, więc ta strona nie będzie wyświetlana w wyszukiwarce. Możesz sprawdzić ten adres URL, żeby zobaczyć, który adres URL jest traktowany przez Google jako kanoniczny w przypadku tej strony.
Jeśli uważasz, że robot Google wybrał odpowiednią stronę jako kanoniczną, nie musisz nic więcej robić. Jeśli uważasz, że robot Google wybrał zły adres URL jako kanoniczny, możesz wyraźnie oznaczyć kanoniczny adres URL w przypadku tej strony. Jeśli uważasz, że ta strona nie jest duplikatem strony kanonicznej wybranej przez Google, upewnij się, że jej zawartość znacznie się różni.
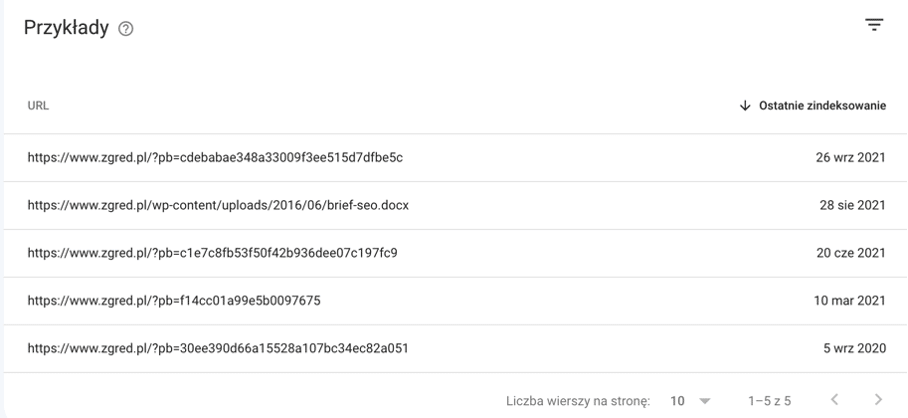
Jeżeli nie masz wdrożonego canonical to teoretycznie Google powinien go sobie sam wybrać na zasadzie „self”. Niestety tak dobrze nie jest. W zakładce o tym, że nie ustawiłeś prawidłowego canonical mogą się pojawić strony z parametrami, pliki PDF (nota bene można w nich ustawić canonical), Doce itd.
W przypadku ze screena powyżej pokazany jest adres URL z parametrem i informacja o braku oznaczonej strony kanonicznej. Szkopuł w tym, że jest ustawiona. Dlatego „olewamy” ten alarm i przechodzimy do dalszych analiz.
Nie znaleziono (404)
Oznacza to, że dany adres URL nie istnieje. Robot wyszukiwarki wykrył URL, ale ten zwraca błąd 404. Być może doszło do nieprawidłowości w adresie w linkowaniu wewnętrznym albo usunąłeś dany materiał z serwisu – to najczęstsze przyczyny tego błędu. Jeśli strona została przeniesiona, to skorzystaj z przekierowania 301.
Duża liczba błędów 404 (poza 429) nie wpływa na wykorzystanie crawl budgetu (przynajmniej tak deklarują Googlersi). Tylko czemu lepiej jest ich nie mieć i zrobić przekierowania? Ciekawe.
Robot Google, zamiast przeglądać istniejące podstrony i je indeksować, traci zasoby na materiały, które nie istnieją. Dlatego śledź błędy znalezione przez Google. Kiedy klikniesz lupkę przy problematycznym adresie URL z listy, to dowiesz się, jakie są przyczyny wykrycia błędu 404, np. adres znajduje się w mapie witryny. Usuń te przeszkody.
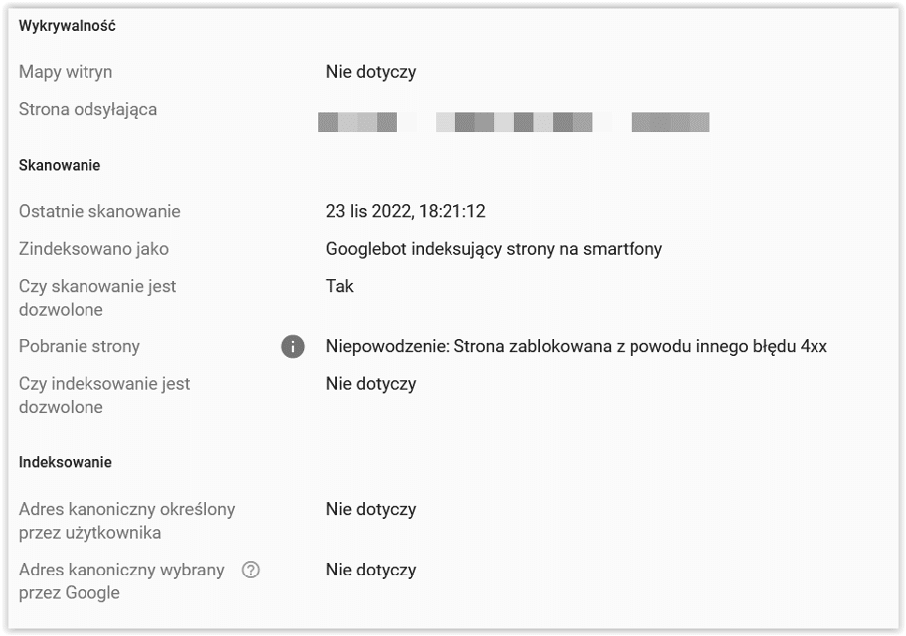
Strona zablokowana z powodu innego błędu 4xx
404 to nie jest jedyny błąd, który może spowodować, że Google nie zindeksuje danego materiału. Dojść może też do innego błędu 4xx. Kliknij ten rodzaj przyczyny na liście, a następnie wybierz ikonę lupki, aby sprawdzić szczegóły. W tym przypadku często chodzi o odniesienia do plików, które nie powinny być dostępne dla internautów, np. do panelu zarządzania stroną.
Pozorny błąd 404
W takim przypadku dochodzi do rozbieżności pomiędzy tym, co widzą użytkownik i robot Google. Może być tak, że dany materiał zwraca kod 200, co oznacza, że wszystko jest w porządku. Tymczasem internauta odwiedza stronę i trafia na pustą albo częściowo zapełnioną witrynę bądź informację o błędzie 404. Sprawdź, na czym polega problem w danym przypadku, jaki kod zwraca serwer i wyeliminuj komplikację. Najprawdopodobniej strona powinna zwracać błąd 404.
Strona wykryta obecnie niezindeksowana
Strona została już znaleziona, ale nie została jeszcze zindeksowana przez Google. Najczęstszą przyczyną tego stanu jest to, że próba zindeksowania danego adresu URL przez Google mogła przeciążyć stronę i indeksowanie zostało zaplanowane na później. Właśnie dlatego data ostatniego indeksowania w raporcie jest pusta.
W tym przypadku Google uzyskało dostęp do danego materiału, nie występują żadne trudności, ale URL czeka na indeksację w kolejce. Jeśli chcesz przyspieszyć moment, w którym materiał trafi do indeksu, to dodaj na stronie linki wewnętrzne, które do niego prowadzą. Ewentualnie umieść odnośniki zewnętrzne, tzn. na innych stronach WWW, kierujące do tego URL-a.
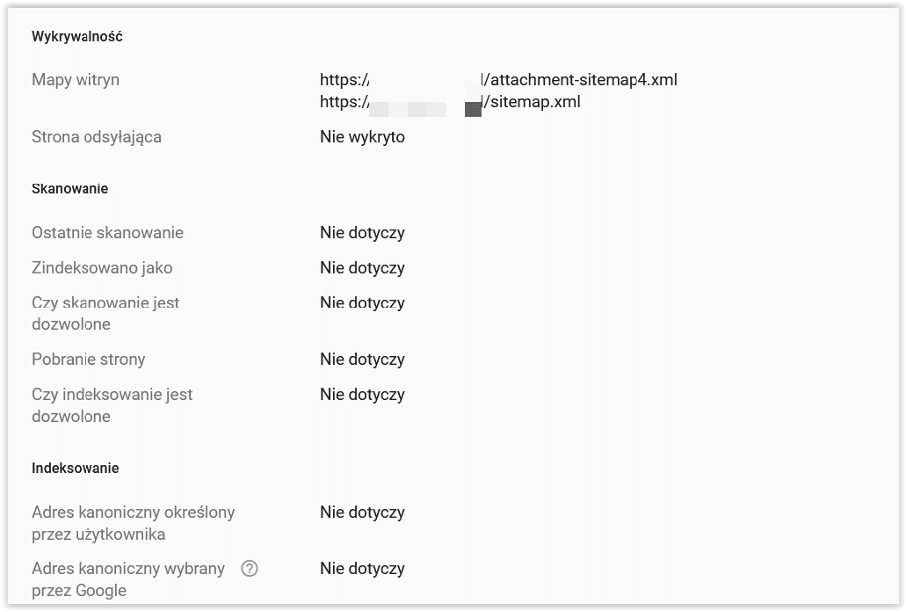
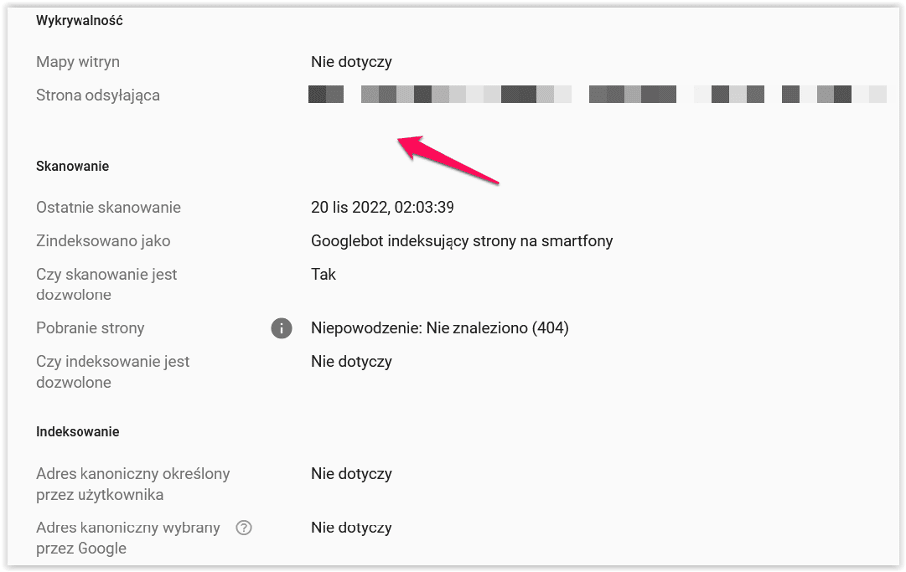
Od razu pokazuję drugi screen celem wyjaśnienia:

Czyli patrząc na manual, Googlebot wykrył stronę ale nie przesłał jej do indeksacji bo się po drodze wywrócił. Dlatego też nie ma daty w ostatniej kolumnie. Adresy URL w tym serwisie istnieją.
Ciekawostka: strona, w miarę swojego życia, może mieć problemy z indeksacją więc w tej sekcji dane mogą co jakiś czas się pojawiać dlatego warto tu zaglądać i weryfikować czy coś się nie „wysypało”. Może się okazać, że problemy z crawlowaniem oraz indeksacją wynikają ze źle dobranego serwera (np. jest już za mało do potrzeb serwisu).
Strona zeskanowana, ale jeszcze niezindeksowana
Strona została zeskanowana, ale nie została jeszcze zindeksowana przez Google. Strona może zostać zindeksowana w przyszłości. Nie ma potrzeby ponownego przesyłania tego adresu URL do zeskanowania.
Google znalazło ten adres URL, zeskanowało go, ale jeszcze nie zindeksowało. Nastąpi to w przyszłości. Nie ma tutaj błędu (no prawie). Możesz przyśpieszyć indeksowanie tymi samymi metodami, co w przypadku poprzednim – linkami wewnętrznymi lub zewnętrznymi.

I tutaj pojawia się jednak potrzeba zastanowienia nad danymi, które tutaj pokazałem. Okazuje się, że Google w tej zakładce pokazuje adresy URL, które:
- Zawierają /feed/, który nigdy nie będzie zaindeksowany ale go skanuje
- Subdomena seo.zgred.pl, która od dawna nie istnieje i jest przekierowana
- Tagi, które są skasowane z subdomeny i przekierowane
- Mogą się tutaj pojawić adresy URL z parametrami (filtracje i sortowania ze sklepów, programy partnerskie)
Innymi słowy: Googlebot crawluje takie adresy URL, skanuje ale ich jeszcze nie zaindeksował. Dopiero w trakcie indeksacji zdecyduje czy i na ile rzeczywiście je przesłać do indeksu.
Uwaga: w tej sekcji mogą pojawiać się co jakiś czas adresy URL ponieważ Googlebot mógł natrafić na problemy w trakcie skanowania. Warto do tej zakładki zaglądać raz na kwartał i weryfikować sytuację.
Strona zindeksowana bez zawartości
Ta strona pojawia się w indeksie Google, ale z jakiegoś powodu nie udało się odczytać jej zawartości. Możliwe przyczyny to maskowanie strony lub format strony, którego Google nie może zindeksować. Nie jest to związane z blokowaniem za pomocą pliku robots.txt. Sprawdź stronę – zwłaszcza jej sekcję Stan.
Bardzo rzadki przypadek dotyczy głównie sklepów internetowych. Zdarzyło się w kilku przypadkach, że Googlebot zaindeksował podstronę w taki sposób, że widoczne było jedynie menu górne oraz stopka a w środku pusto.
Strona zablokowana przez plik robots.txt
Możliwe, że wykorzystałeś plik robots.txt do zablokowania indeksowania danego materiału. Ta metoda nie zawsze jest skuteczna i Google nie zaleca jej, jeśli nie chcesz, żeby URL znalazł się w wynikach wyszukiwania. Jeżeli do danego materiału prowadzą linki zewnętrzne, to wtedy i tak może się znaleźć w indeksie Google. Przy czym robot go zindeksuje, ale nie będzie skanować. Różnica w stosunku do standardowego indeksowania polega na tym, że Google pokaże jedynie bardzo ograniczoną treść z witryny.
Jeśli chcesz sprawdzić dany URL pod kątem blokowania w robots.txt, to skorzystaj z tego narzędzia: https://www.google.com/webmasters/tools/robots-testing-tool. Jak naprawić błąd? W przypadku gdy adres ma trafić do Google, to usuń z robots.txt kod odpowiedzialny za blokadę.
Strony filmów
W menu Indeksowanie znajdziesz również pozycję dotyczącą stron filmów. Będą tam informacje dotyczące stanu indeksowania plików wideo.
Tutaj również możesz znaleźć dane o przyczynach braku indeksacji, o ile oczywiście masz filmy na stronie.
W tym artykule został dodany filmik z Youtube. Dzięki temu niniejsza publikacja pojawi się w zakładce z filmami. Ciekawostka: embedowanie filmików sprzyja indeksacji 😉
Mapy witryn
Kolejną pozycją w menu Indeksowanie są Mapy witryn. Jeśli masz je dodane, to zwiększasz szanse na indeksację strony. Mapa jest listą adresów URL z Twojej witryny. Umieść w niej te, które chcesz, aby znalazły się w Google. Nie chodzi tutaj wyłącznie o odnośniki do podstron, ale także o zdjęcia i materiały wideo.
Kiedy klikniesz tę opcję w menu, to wyświetli się lista map, o ile są one dodane. Zweryfikujesz, jaki jest ich stan, tzn. czy plik jest prawidłowy. Kiedy przesłano mapę i nastąpił ostatni odczyt? Zobaczysz także liczbę wykrytych adresów URL. Na końcu każdego wiersza będzie ikona wykresu. Kliknij ją, aby sprawdzić, ile URL-i zostało zindeksowanych.
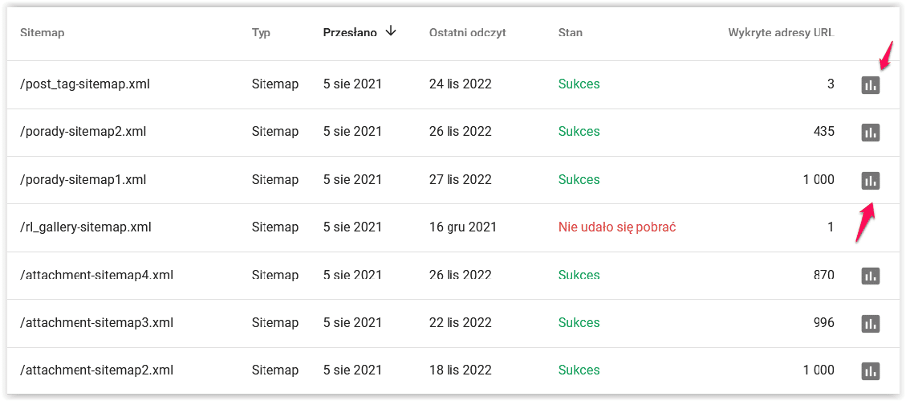
W przypadku map, których stan wyświetla się na czerwono, możesz upewnić się, z czego wynika nieprawidłowość. Co spowodowało, że Google nie może korzystać z tej mapy? Być może chodzi o błędny adres?
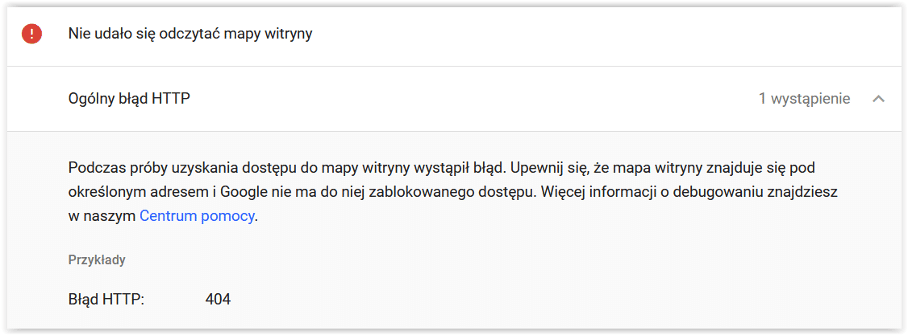
Nad tabelą z listą map jest opcja dodania kolejnych. Musi to być URL w Twojej domenie. Jak wygenerować mapę? Np. za pomocą popularnych wtyczek SEO do WordPress, jak All in One SEO czy Yoast SEO. Zrobisz to również w programie Screaming Frog i za pomocą generatorów online.
Warto zajrzeć do pomocy w Google pod adresem: https://developers.google.com/search/docs/crawling-indexing/sitemaps/build-sitemap ponieważ na samym końcu Google informuje o możliwości pingowania map serwisu. Dlatego jeśli przed dłuższy czas Googlebot nie aktualizuje plików map w GSC możan je „przepingować”.
Usunięcia
Czwartą i ostatnią pozycją w menu Indeksowanie są Usunięcia. Skorzystaj z niej, jeśli chcesz wykluczyć jakiś adres URL z indeksu Google.
Kiedy klikniesz tę opcję, zobaczysz listę URL-i, których dotyczyły dotychczasowe zapytania. Jeśli chcesz dodać kolejne, to wyślij Nowa prośba.
Ta metoda umożliwia zablokowanie indeksowania danego materiału na około 6 miesięcy. Jeśli chcesz, aby URL na stałe zniknął z Google, to wstrzymaj jego indeksowanie za pomocą tagu noindex: <meta name=”robots” content=”noindex”>. Dodaj go w sekcji <head> strony. Ewentualnie usuń adresy, których nie chcesz indeksować.

UWAGA: tę opcję wykorzystywać uważnie i z rozwagą, ponieważ można sobie wyindeksować podstrony odpowiedzialne za ruch lub nawet cały serwis.
Indeksowanie w GSC – podsumowanie
W raportach związanych z indeksowaniem strony znajdziesz mnóstwo ciekawych informacji. Zaglądaj tam systematycznie, monitoruj błędy i je eliminuj. Mogą one negatywnie wpływać na widoczność Twojej witryny.
W przypadku małych serwisów takie analizy wystarczy robić ra zna kwartał i weryfikować informacje zawarte w GSC. W przypadku dużych serwisów zalecałbym weryfikację co kilka tygodni. Problemy z indeksacją są na porządku dziennym i trzeba to kontrolować.
Analizę GSC i informacje tutaj zawarte należy wykonać w ramach technicznego audytu SEO. Jeśli masz problemy związane z indeksacją, pytania – skorzystaj z formularza i zapisz się na konsultacje SEO bo tak jest szybciej i skuteczniej.
Przydatne linki:
- Raport Stan w indeksie https://support.google.com/webmasters/answer/7440203?hl=pl
- Zgredobook, w którym jest wiele artykułów o indeksacji: bit.ly/zgredbook
- Czemu się nie indeksuje – wywiad ze Mną: https://www.devagroup.pl/blog/content-is-king-wywiad-z-pawlem-gontarkiem





Mam stronę na WP. Google często dla nowej treści zamiast w wyszukiwarce wyświetlać docelową treść np domena.pl/podstrona.html wyświetla w wynikach link do głównego obrazka.
Gdzie leży problem?
Podejrzewam, że chodzi o brak przekierowania z obrazka na treść i obrazki są indeksowane osobno. Pomoże ustawienie we wtyczce Yoast odpowiedniego przekierowania lub zainstalowanie wtyczki WP Attachement redirect (chyba tak się nazywa).
Dodam, że w przypadku podstron „Strona wykryta obecnie niezindeksowana” proces indeksacji można łatwo przyspieszyć korzystając z addurl (ikona lupy przy adresie):
https://i.paste.pics/d627672d32664e19a170e4c5e62d2b42.png
@Zgred – słabe to CTA dałeś na końcu artykułu 🙂
Weryfikacja indeksacji to jedna z obowiązkowych czynności w procesie pozycjonowania. Ciekawy tekst, poruszający wiele kwestii, o których nie wie wielu włascicieli stron www.
Jako osoba wchodząca dopiero w temat optymalizacji i pozycjonowania stron bardzo doceniam tego typu artykuły w przystępnej formie opisujące ważne dla pozycji strony informacje. Wszelkiego typu statystyki dają najlepszy pogląd na kondycję strony, punktują słabe elementy strony i pokazują gdzie jest dobrze. Sam staram się analizować statystyki indeksowania, ale każda fachowa pomoc, ciekawa informacja jest na wagę złota.
Z tekstu wynika wniosek, że bardzo ważne jest śledzenie statystyk indeksowania w Google Search Console. To narzędzie staje się kluczowym elementem strategii SEO, pozwalając zrozumieć, jak wyszukiwarka ocenia i interpretuje naszą stronę. Bardzo wartościowym aspektem artykułu jest również podkreślenie, że analiza tych statystyk to proces dynamiczny, wymagający ciągłego monitorowania i dostosowywania strategii.
Ale z komentarza wynika, że posmapowałeś linkiem 😉
Po ostatnim updacie doszła jeszcze jedna, bardzo tajemnicza kategoria- czyli GSC twierdzi, że dana podstrona jest w indeksie i niby wszystko jest OK, ale z poziomu wyszukiwarki nie da się do niej dostać, nawet wpisując w szukajkę goły URL 🙂
Raczej jest to normalka – komenda site od dawna działa różnie.
Site nie pokazywało wszystkiego już od dawna, natomiast jeżeli wbiło się w wyszukiwarkę URL danej podstrony, albo jakiś fragment tekstu to w SERP się to pojawiało (w najgorszym przypadku gdzieś na dole), a teraz nie ma w ogóle- chociaż GSC twierdzi, że strona figuruje w indeksie.
Google wybiera stronę główną jako kanoniczną, a nie podstronę wybraną przez użytkownika (mającą canonical sam na siebie). Strona główna ma „mobile redirect” i canonical na podstronę, ale to nic nie daje, bo dalej nie widać jej w GSC (widnieje tylko w zakładce indeksowanie stron pod „Duplikat, wyszukiwarka Google wybrała inną stronę kanoniczną niż użytkownika”).
Podstrona wybrana przez użytkownika ma mało treści, ok. 500 znaków (jest zduplikowany zewnętrznie), oraz ma w tytule „produkt1, produkt2, produkt3 – producent” i jest widoczna w top 10 na frazy produkt1, produkt2, produkt3, produkt1 producent, produkt2 producent… Strona główna ma w tytule tylko nazwę firmy, ale ma ok. 1500 znaków treści, w której również są zawarte frazy z podstrony.
Backlinki prowadzą tylko do strony głównej. Do podstrony prowadzą tylko linki wewnętrzne z menu mające anchor „produkty”. Czy tutaj pomoże dodanie więcej tekstu na podstronę? Czy dobrym rozwiązaniem będzie przekierowanie 301 pełne, a nie tylko mobile redirect?
a czemu stosujesz mobile redirect? po co? z czego to wynika?
Wygląda na to, że albo masz bałagan w przekierowaniach i canonicalu albo po prostu Google wybrało najlepsza opcję pod kątem optymalizacji i uzytkownika.
Jesli coś ma przekierowanie to jasne jest, że canonical zostanie zignorowany.
Podstrona ładniej wygląda na mobilnych.To jest WordPress i canonicale domyślnie są dobrze ustawione.To mnie dziwi że jak sprawdzam podstronę w gsc to jest komunikat „Adres URL nie znajduje się w Google” pomimo że ona dobrze rankuje. Co w tej sytuacji najlepiej zrobić.Wylaczyć mobilne przekierowanie, aby Google odczytało canonical na podstronę i dodać na podstronie więcej znaków, aby Google ją wybralo jako kanoniczną?Czy może lepiej zrobić nie tylko mobilne a pełne przekierowanie 301 strony głównej na podstronę?
Albo wyindeksować stronę glówną?Zaznaczam że w gsc jest widoczna tylko strona główna m.in w zakładce skuteczność. Jak sprawdzam frazy na jakie zdobywa ona kliknięcia to jakby zdobywała ruch podstrony produkty bo podstrona produkty jest tylko w top 10 na te frazy.
Bez adresu strony nie umiem doradzić. Tak jak napisałem – skoro jest jakiekolwiek przekierowanie to Google nie pokaze tej strony i będzie pisało, że storna nie jest w indeksie bo jest 301. Wiec zadne canonical nie pomoże. Przekierowania są czytane i analizowane na poziomie połaczenia a canonical na poziomie aplikacji czyli po połaczeniu. Zatem najpierw zadziała 301 i do analizowania podstrony nie dojdzie.
Link do podstrony, której google nie chce wybrać jako kanonicznej https://cutt.ly/keyJ4qZ2
Zamiast niej wybiera stronę główną, która jak się okazało ma przekierowanie mobile 302 na nią.
Canonical ze strony głównej na podstronę nie pomaga.
Nie no takich rzeczy sie nie robi. Nie wolno robić przekierowań na mobilce kiedy na desktop nie ma tego przekierowania. Canonical wybrany prawidłowo – strona /produkty-2/ jest po prostu słaba pod kątem SEO. Canonical z głównej na produkty-2 nigdy nie zadziała ponieważ strona główna i podstrona NIE SĄ duplikatem. Mają oryginalne treści i Googlebot zadziałał jak najbardziej prawidłowo.
Prosze zdjąc przekierowanie 302 na mobilne – żadnych takich dziwnych rzeczy prosze nie robić
Na stronie /produkty-2/ dodac opis co tutaj się znajduje (dłuzszy) moze być na dole i canonical sam na siebie (self)
Na stronie głównej prosze ustawić canonical na stronę główną a nie na /produkty-2/
Zrobiłeś bajzel na stronie z canonicalami.
A ja mam podobny problem bo Google zamiast podstrony wybiera stronę główną jako kanoniczną . Czy ten problem można też rozwiązać canonicalem ze strony głównej na podstronę i umieszczenie na podstronie takich samych tekstów jak na głównej, aby canonical załapał lub przekierowaniem 301 strony głównej na podstronę?
Nie -takich rzeczy nie rozwiązuje się canonicalem. Trzeba kombinowac z tekstami, seo i optymalizacją.
Mam zagadkowy przypadek z mapą witryny w pliku o nazwie: sitemap.xml
Po dodaniu „sitemap.xml” do SC ostatni odczyt mapy jest archiwalny z 2022r i mapa nie jest odczytywana.
Natomiast gdy dodam ten sam plik mapy pod jakąkolwiek inną nazwą np: sitemap2.xml odczyt i indeksowanie jest normalne.
W czym może być problem?
Trzeba zweryfikować na poziomie serwera czy Googlebot w ogóle crawluje sitemapę, ustawienia firewall’a lub uprawnienia do pliku …
Hej
Dodalem w gsc poza sitemap index rownnież dodatkowo sitemapy bloga i stron produktowych (ok 2 tyg temu) i wciąż nie mogę zobaczyć dla nich danych czyli performance mimo to, że były ostatnio przeczytane wczoraj…
Dane pojawia się w ciagu … nawet kilku tygodni. GSC nie działa adhoc.