Budowa nowej strony internetowej powinna iść w parze z jej optymalizacją pod wyszukiwarki internetowe. W końcu każdemu, kto buduje stronę zależy na tym, aby odwiedziało ją jak najwięcej użytkowników. Niestety bardzo często bywa tak, że deweloperzy pomimo budowy estetycznych i funkcjonalnych stron, zapominają o aspektach, które mają wpływ na pozycjonowanie witryny. Często popełniają również drobne błędy, wynikajace z gapiostwa, jak np. przeniesienie dyrektyw dla robotów z wersji testowych. W poniższym artykule zebrałem 20 najczęściej popełnianych błędów przy budowe stron internetowych, których wyeliminowanie pozwoli na oddanie strony internetowej zgodnie ze sztuką SEO. Przedstawiłem również walidatory oraz przykłady prawidłowych rozwiązań problemów. Zapraszam do lektury ?
1. Indeksowanie wersji deweloperskich
Kopie serwisów na wersjach deweloperskich to jeden z najpopularniejszych błędów popełnianych przez osoby budujące strony. Kopie serwisów nie są blokowane przed robotami wyszukiwarek, przez co są odwiedzane i dodawane do indeksu. Powielanie treści to jeden z poważniejszych problemów, który może znacząco wpływać na widoczność serwisu. Środowisko testowe to najczęściej subdomena pod adresem:
- test.nazwadomeny.pl
- beta.nazwadomeny.pl
- beta2.nazwadomeny.pl
Jakie jest rozwiązanie problemu?
Blokada wersji deweloperskiej strony poprzez zastosowanie dyrektywy ?noindex? w tagu meta robots lub zastosowanie zapisu Disallow: / w pliku robots.txt.
Uwaga!
Jeżeli nietety zdarzyło nam się zapomnieć o zablokowaniu wersji deweloperskiej i strony zostaną dodane do indeksu wyszukiwarki, należy skorzystać z dyrektywy ?noindex? w tagu meta robots. Zastosowanie zapisu Disallow: / który zabroni robotom odwiedzać witrynę, może nie spowodować usunięcia stron z indeksu wyszukiwarki.
Walidator:
Dyrektywy dla robotów możemy sprawdzić na kilka sposobów. Możemy zajrzeć po prostu do źródła strony poprzez użycie kombinacji klawiszy Ctrl + U. Możemy także skorzystać z dowolnej wtyczki do sprawdzania SEO Meta np.: SEO Meta in 1 Click lub Open SEO stats.
2. Kopie serwisu pod różnymi adresami
Duplikacja strony głównej pod różnymi adresami to nadal, bardzo często występujący problem. Kopie serwisu występują zazwyczaj ze względu na błędnie zaimplementowany certyfikat SSL lub brak ustawionych przekierowań 301. Strona główna może być zduplikowana pod następującymi adresami:
- pl/
- index.html
- index.php
- http://
- http://www.
- https://
- https://www.
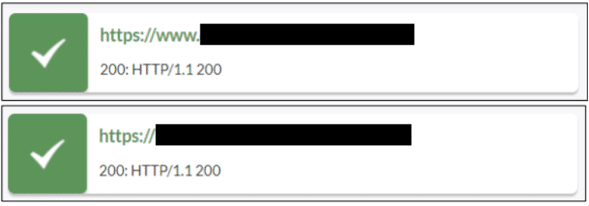
Jakie jest rozwiązanie problemu?
Prawidłowe ustawienie przekierowań 301. Każda kopia serwisu powinna być przekierowana permanentnie i bezpośrednio na wersję kanoniczną.
Walidator:
Możemy sprawdzić konfigurację serwera oraz prawidłowość wdrożenia certyfikatu SSL. Możemy użyć również popularnych wtyczek do sprawdzania odpowiedzi serwera i wyłapywania przekierowań dla poszczególnych adresów URL takich jak: Redirect Path lub Link Redirect Trace.
3. Przenoszenie dyrektyw dla robotów z wersji deweloperskich
Kolejnym, równie popularnym problemem jest przenoszenie dyrektyw dla robotów wyszukiwarek z wersji deweloperskich. Mówiąc o dyrektywach dla robotów, mamy na myśli:
Przenoszenie zapisu Disallow: / z pliku robots.txt
![]()
Przenoszenie dyrektywy ?noindex? w tagu meta robots
![]()
Przenoszenie adresu z wersji deweloperskiej w tagu rel=?canonical?
![]()
Jakie jest rozwiązanie problemu?
Po przeniesieniu zawartości serwisu na adres docelowy, należy sprawdzić zawartość tagów meta robots i canonical oraz pliku robots.txt.
Walidator:
Możemy skorzystać z narzędzia Screaming Frog (narzędzie płatne, bezpłatne do maksymalnie 500 adresów URL) lub z darmowych wtyczek do sprawdzania SEO Meta oraz dyrektyw dla robotów: SEO Meta in 1 Click oraz Open SEO Stats. Należy również zweryfikować zawartość pliku robots.txt.
4. Blokowanie zasobów CSS/JS w pliku robots.txt
Kolejnym częstym błędem jest blokowanie katalogów w pliku robots.txt, w których znajdują się arkusze CSS lub skrypty JS. Zablokowanie w/w zasobów może powodować problemy z prawidłowym wyrenderowaniem witryny i dotarciem do wszystkich elementów przez roboty wyszukiwarek.
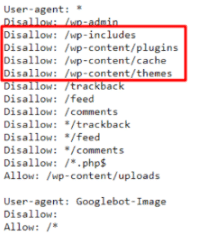
Jakie jest rozwiązanie problemu?
Weryfikacja pliku robots.txt ? nie należy blokować katalogów w których znajdują się arkusze CSS oraz skrypty JS.
Walidator:
Weryfikacja pliku robots.txt ? możemy także skorzystać z opcji ?Pobierz jako Google? w Google Search Console oraz z testu ?Mobile Friendly? od Google.
5. Brak używania adresów kanonicznych
Stosowanie adresów kanonicznych jest obowiązkowe w przypadku stron filtrowania, sortowania oraz adresów z parametrami. W przypadku sklepów internetowych, zastosowania filtru ze względu na rozmiar, powoduje dopisanie do adresu URL ciągu znaków z parametrem odpowiadającym za to filtrowanie. W przypadku, gdy nie zastosoujemy tagów kanoniczych, roboty Google mogą dodać do indeksu ogromną liczbę zduplikowanych adresów url. Przykład:
Adres kategorii: https://ccc.eu/pl/damskie/buty/botki
Adres kategorii po zastosowaniu filtru rozmiar 39: https://ccc.eu/pl/damskie/buty/botki?priceFilter%5Bmin%5D=21&priceFilter%5Bmax%5D=339.99&filter%5B195539%5D%5B0%5D=46721
Prawidłowe zastosowanie adresu kanonicznego:

Jakie jest rozwiązanie problemu?
Stosowanie adresów kanonicznych w przypadku stron filtrowania, sortowania oraz w przypadku innych adresów z parametrami.
Walidator:
Możemy skorzystać z narzędzia Screaming Frog lub darmowych wtyczek takich jak SEO Meta in 1 click lub Open SEO stats.
6. Błędnie zbudowana paginacja
Kolejny błąd, który jest bardzo często popełniany, to błędnie zbudowana paginacja na stronie. Poprzez błędnie zbudowaną paginację, mamy na myśli indeksowanie kolejnych stron stronnicowania lub błędne wskazywanie pierwszej strony paginacji.
Indeksowanie kolejnych stron stronicowania:
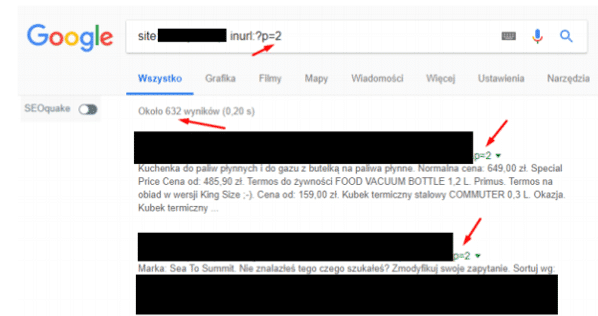
Błędnie wskazywana pierwsza strona paginacji (z parametrem np. ?p=1):

Jakie jest rozwiązanie problemu?
Blokowanie kolejnych stron paginacji poprzez zmianę dyrektywy w tagu robots na noindex, follow oraz wskazywanie kanonicznej pierwszej strony paginacji (bez parametru np. ?p=1)
Walidator:
Możemy skorzystać z narzędzia Screaming Frog bądź darmowej wtyczki np. SEO Meta in 1 Click
7. Zapętlanie przekierowań
Przekierowania adresów URL powinny być maksymalnie bezpośrednie, bez dodatkowych, zbędnych ogniw tworzących pętle przekierowań. Bardzo częstym przypadkiem jest zapętlenie przekierowań strony głównej, przykład:

Jakie jest rozwiązanie problemu?
Rozwiązaniem problemu jest weryfikacja konfiguracji po stronie serwera oraz ustawienie bezpośrednich przekierowań 301.
Walidator:
Możemy użyć popularnych wtyczek do sprawdzania kodu odpowiedzi serwera oraz sprawdzania przekierowań takich jak np: Redirect Path lub Link Redirect Trace.
8. Błędne stosowanie atrybutu hreflang
Hreflang to atrybut, który w 2011 został wprowadzony przez Google, aby poinformować roboty wyszukiwarek o innych wersjach językowych danego serwisu.

Najczęstszym problemem związanym ze stosowaniem hreflangów, jest brak tagów powrotnych na przykład:
Na wersji językowej ?pl? mamy prawidłowo wskazane inne wersje językowe np.: ?en?, ?de?, ?fr? itp. Natomiast na innej wersji językowej np. ?fr? nie mamy tagów powrotnych, czyli w atrybucie hreflang nie wskazujemy innych wersji językowych.
Jakie jest rozwiązanie problemu?
Stosując tag link rel=?alternate? z atrybutem hreflang, należy pamiętać o tagach powrotnych.
Walidator:
Możemy skorzystać w raportu ?kierowanie międzynarodowe? w panelu Google Search Console. Możemy także skorzystać z narzędzia screming Frog lub skorzystać z walidatorów online np: – https://www.sistrix.com/hreflang-guide/hreflang-validator/
9. Brak linkowania wewnętrznego
Linkowanie wewnętrzne do najważniejszych kategorii, podkategorii lub produktów pomaga w rozprzestrzenieniu mocy linków zewnętrznych do tych najważniejszych sekcji serwisu. Pomaga również w ich indeksowaniu przez roboty wyszukiwarek internetowych. Bardzo często, linkowanie wewnętrzne nie jest w ogóle wykorzystywane.
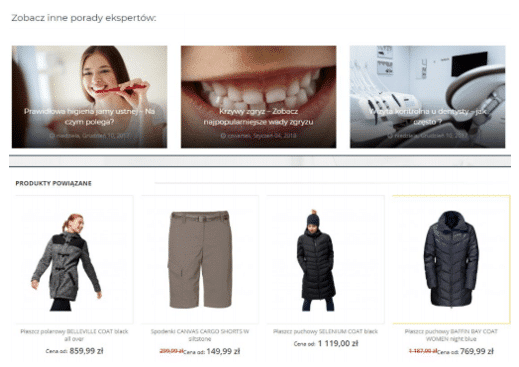
Jakie jest rozwiązanie problemu?
W przypadku sklepów internetowych należy obowiązkowo stosować moduł related products, natomiast w przypadku stron contentowych moduł related posts.
Walidator:
Do sprawdzenia struktury linkowania wewnętrznego możemy użyć narzędzia Screaming Frog, które podpowie nam jakimi kotwicami są linkowane najważniejsze podstrony oraz jak głęboko znajdują się one w strukturze serwisu.
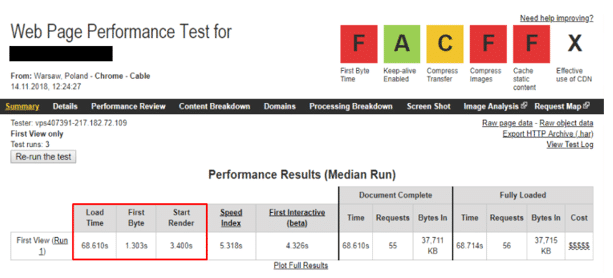
10. Problemy z prędkością ładowania witryny
Prędkość ładowania witryny jest jednym z kluczowych czynników rankingowych, branych pod uwagę przez wyszukiwarkę Google. Najczęściej, opóźnienia powodują zbyt duże grafiki dodawane na stronę, brak wykorzystania pamięci podręcznej, zbyt duża liczba wykonywanych requestów, a także czynniki czysto techniczne wpływające na wydajność strony internetowej takie jak skomplikowane zapytania do bazy danych czy wykorzystanie frameworków/bibliotek pożerających ogromną liczbę zasobów.
Jakie jest rozwiązanie problemu?
Walidacja strony przy użyciu wielu dostępnych narzędzi na rynku i wdrożenie rekomendowanych rozwiązań. W przypadku stron opartych na WordPress można skorzystać z poniższych wtyczek:
- Do optymalizacji zdjęć: np. WP Smush lub EWWW Image Optimizer
- Do wyczyszczenia bazy danych ze zbędnych zapytań: Optimize Database after Deleting Revisions
- Do cache: WP Super Cache lub W3 Total Cache
- Do zmniejszenia rozmiaru HTML, JS, CSS: Autooptimize
- Do optymalizacji ładowania plików JS: Async JavaScript lub Scripts to Footer
Warto sprawdzić również wykorzystywaną wersję PHP i w razie potrzeby dokonać aktualizacji do wersji 7.3, a także zadbać o dobry i wydajny serwer.
Walidator:
Warto skorzystać z poniższych, darmowych walidatorów:
- PageSpeed Insights bazujący obecnie na danych z Lighthouse
- Webpagetest.org
- GTMetrix
- Pingdoom
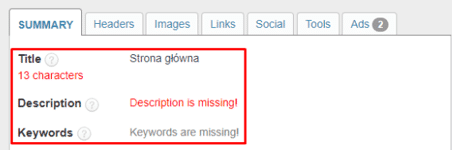
11. Brak optymalizacji Meta SEO
Przy budowie storny Internetowej, nie mając nawet większego pojęcia o SEO i analizie słów kluczowych, można dokonać podstawowej optymalizacji znaczników Meta. W wielu przypadkach, znaczniki Meta Title oraz Meta Keywords są powielane na każdej podstronie serwisu i brzmią na przykład „strona główna”.
Jakie jest rozwiązanie problemu?
Można dokonać podstawowej optymalizacji znaczników Meta, na przykład umieścić nazwę danej kategorii lub produktu w znaczniku Meta TITLE. Należy również pamiętać o tym, aby nie uzupełniać znacznika Meta KEYWORDS, który od 2009r. nie jest wspierany przez Google i nie jest on czynnikiem rankingowym.
Walidator:
Do masowej weryfikacji SEO Meta najlepszym narzędziem jest Screaming Frog. Możemy również skorzystać z darmowych wtyczek takich jak: SEO Meta in 1 click lub Open SEO Stats.
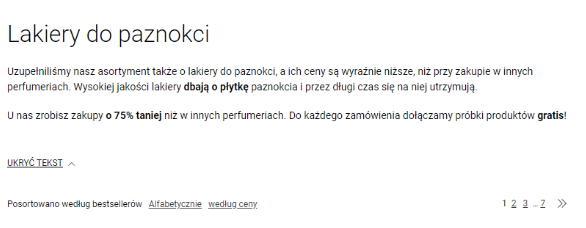
12. Brak warstawy tekstowej w serwisie
Bardzo częstą sytuacją w przypadku nowych stron internowych jest brak wyznaczonego miejsca na warstwę tekstową. Projekt strony nie zakłada miejsca na blok tekstowy, przez co nie ma potem możliwości dodania kilku linijek opisu kategorii.
Jakie jest rozwiązanie problemu?
Podczas budowy witryny internetowej należy pamiętać o warstawie tekstowej i zaprojektowaniu miejsca na blok tekstowy.
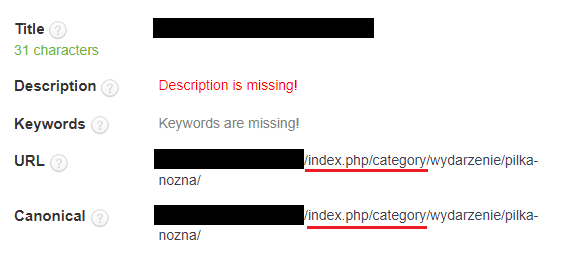
13. Brak optymalizacji adresów url
Stosowanie przyjaznych adresów URL to podstawa optymalizacji strony. Adresy powinny być maksysmalnie krótkie oraz zawierać słowa kluczowe oddzielane myślinikami, bez polskich znaków, bez wielkich liter. Nie należy stosować nieporzebnych katalogów.
Jakie jest rozwiązanie problemu?
Należy pamiętać o stosowaniu przyjaznych adresów URL.
Walidator:
Do masowej weryfikacji adresów URL możemy skorzystać z narzędzia Screaming Frog, dzięki któremu dotrzemy do wszystkich adresów podlinkowanych wewnętrznie.
14. Brak optymalizacji nagłówków H1/H2
Należy zadbać, aby każdy typ strony (szablon) posiadał odpowiednio ustaloną strukturę nagłówków HTML. Tytuł strony powinien być oznaczony jako nagłówek najwyższego rzędu H1, a kolejne ważne informacje powinny być oznaczone kolejnymi wartościami tzn. H2/H3 i tak dalej.
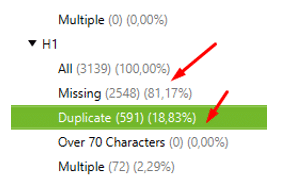
Jakie jest rozwiązanie problemu?
Ustawienie hierarchi nagłówków HTML dla każdego szablonu strony.
Walidator:
Do masowej weryfikacji stuktutry nagłówków H1/H2 możemy użyc Screamieng Froga. Dla pojedyńczych adresów URL możemy użyć darmowych wtyczek takich jak SEO Meta in 1 click lub open SEO stats.
15. Popsute linki wewnętrzne
Popsute linki, które znajdują się w nawigacji serwisu, to kolejny z dość powszechnie występujących błędów. Zazwyczaj błąd ten pojawia się podczas przenoszenia starej struktury serwisu oraz podczas umieszczenia odnośników na stornie ?z palca?. Takie odnośniki, jeżeli następnie zostaną usunięte, powodują właśnie powstawanie błędów 4xx.
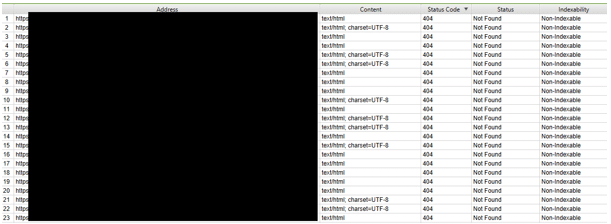
Jakie jest rozwiązanie problemu?
Pełen crawl serwisu, dotarcie do wszystkich podlinkowaych adresów zwracających błędy oraz podmiana lub usunięcie popsutych odnośników
Walidator:
Pełen crawl serwisu i dotarcie do wszystkich adresów URL. Umożliwia to Screaming Frog.
16. Problemy z mapą witryny xml
Sitemapa.xml jest jednym z ważniejszych plików, do którego sięgają roboty wyszukiwarek internetowych podczas crawlowanwia i indeksowania witryny. W sitemapie powinny znaleźć się wszystkie adresy URL przeznaczone do indeksowania. Niestety, bardzo często mapa witryny w ogóle nie istnieje, zawiera adresy popsute (zwracające kod odpowiedzi 4xx/5xx), zawiera adresy z dodatkowymi przekierowaniami 3xx lub z adresy które w tagu kanonicznym wskazują inny adres. Bardzo często, mapa witryny nie jest ani przesłana w Google Search Console ani nie jest umieszczona w pliku robots.txt
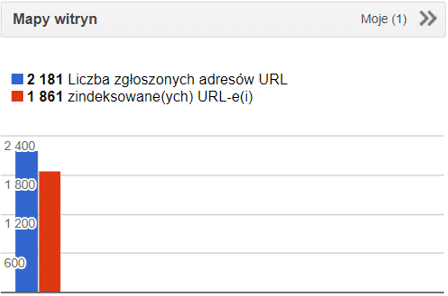
Jakie jest rozwiązanie problemu?
Przygotowanie mapy witryny w formacie xml, zawierającej tylko i wyłącznie adresy przeznaczone do indeksowania, zwracające kod odpowiedzi 200 i canonical wskazujący ?na siebie?.
Walidator:
Mapę witryny można sprawdzić za pomocą narzędzia Screaming Frog oraz z poziomu Google Search Console.
17. Problmy z plikiem robots.txt
Plik robots.txt jest pierwszym plikiem, który sprawdzają roboty wyszukiwarek podczas crawlowania domeny. Dowiadują się z niego, których katalogów strony nie powinny odwiedzać, a także pod jakim adresem URL znajduje się mapa witryny. Bardzo często, witryny internetowe nie posiadają w ogóle pliku robots.txt. Innymi powszechnymi błędami jest blokowanie katalogów z zasobami JS/CSS, brak umieszczenia mapy witryny oraz przenoszenie dyrektywy Disallow: / z wersji deweloperskich witryny.
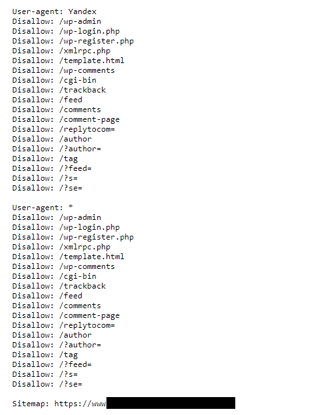
Jakie jest rozwiązanie problemu?
Stworzenie pliku tekstowego robots, dodanie do niego sitemapy, pamiętanie o nie blokowaniu katalogów z zasobami JS/CSS oraz ewentualnie dodanie dyrektywy Allow: /
Walidator:
Czy zasoby JS/CSS nie są blokowane możemy sprawdzić w Google Search Console oraz poprez wykonanie testu optymalizacji mobilnej. Najprostszym walidatorem będzie jednak sprawdzenie zawartości pliku robots.txt, który w zdecydowanej większości stron internetowych znajduje się pod adresem: nazwastrony.pl/robots.txt
18. Stosowanie problematycznych pop-upów
Serwowanie intruzywnych pop-upów, przed pełnym wyrenderowaniem strony, agresywnie atakujących użytkowników jest niezgodne z wytycznymi dla webmasterów. Serwowany pop-up powinien mieć jasny przekaz reklamowy, zostać zaprezentowany w sposób nie itruzywny tzn. po pełnym wyrenderowaniu strony bądź po doknaniu akcji przez użytkownika (np. scroll) oraz zawierać wyraźny przycisk, umożliwający zamknięcie komunikatu. Poniżej przykłady pop-upów intruzywnych, które są niezgodne z wytycznymi Google.

Jakie jest rozwiązanie problemu?
Serwowanie pop-upów po pełnym wyrenderowaniu strony, zawierających jasny przekaz reklamowy, które można w łatwy sposób zamknąć. Nie serwowanie pop-upów na urządzeniach mobilnych!
Walidator:
Warto pamiętać o wytycznych dla webmasterów odnośnie stosowania pop-upów.
19. Brak stosowania danych strukturalnych
Znaczniki danych strukturalnych pomagają algorytmom wyszukiwarek lepiej zrozumieć z jaką treścią mają do czynienia. Ponadto, prawidłowo zaimplementowane dane strukturalne zwiększają atrakcyjność prezentowanego wyniku (oceny, gwiazdki, cena, opinie). Dane uporządkowane są szczególnie istotne w przypadku sklepów internetowych. Niestety, bardzo rzadko są domyślnie przez deweloperów wdrażane, podczas budowy stron internetowych.
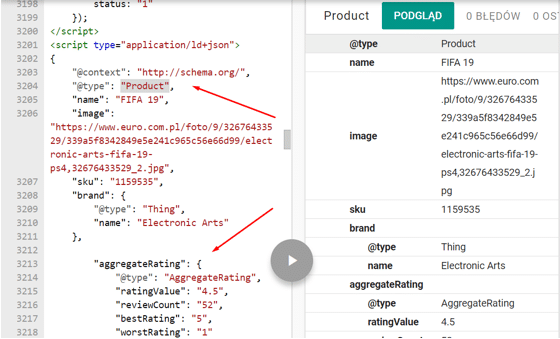
Jakie jest rozwiązanie problemu?
Wdrażanie danych strukturalnych zgodnie ze specyfikacją schema.org,
Walidator:
Do walidowania poprawności wdrożenia danych strukturalnych może posłużyć nam Google Search Console oraz tester danych strukturalnych od Google.
20. Brak aktualizacji WP/wtyczek/szablonu
Brak aktualizacji wordpressa, wtyczek lub szablonu strony to pole do potencjalnych włamów do serwisu. Bardzo często przez dziury w szablonie bądź przez brak aktualizacji komponentów, z których korzysta witryna, dochodzi do hakowania strony oraz podpinania do niej wszelkiego rodzaju tabletek, viagry, tresci dla dorosłych i tym podobnych rzeczy ?
Jakie jest rozwiązanie problemu?
Instalacja wtyczek pochodzących wyłącznie z zaufanych źródeł oraz regularna aktualizacja systemu WordPress, a także szablonu, z któego korzysta witryna.
Walidator:
W przypadku tego problemu, nie mamy walidatorów. Trzeba po prostu pamiętać o regularnych aktualizacjach oraz solidnym zabezpieczeniu swojego WordPressa.
Podsumowanie
Powyżej przedstawione zostały najczęściej popełniane błędy optymalizacyjne podczas budowania lub przenoszczenia stron Internetowych. Wyeliminowanie tylko tych błędów, pozwoli na oddawanie projektów bardzo dobrze przygotowanych pod ich pozyjonowanie w wyszukiwarkach internetowych. Należy oczywiście pamiętać, że 100% optymalizacji możemy osiągnąć tylko poprzez wspólną współpracę dewelopera z SEOwcem.
A wy? Jakie macie doświadczenia w tym zakresie? Dajcie znać! ?





21. Wyłączanie kategorii aby słupki sprzedaży się lepiej zgadzały 😀
Fajna wiadomość w robots.txt 🙂
Na szczęście błędów tych jest coraz mniej. Pozwolę sobie tylko na małą dygresję, co do paginacji. Przy paginacji robot powinien mieć możliwość przejścia po poszczególnych podstronach i ich zaindeksowanie. Oczywiście paginacja powinna być wykonana zgodnie z wytycznymi: każda strona opatrzona atrybutami rel=”next” rel=”prev” oraz rel=”canonical” do samego siebie (a nie tylko do pierwszej strony). Należy także zadbać o indywidualne title i description. Np. poprzez dodanie do nich tekstu – „strona 1”. Proponowane rozwiazanie z tagiem noindex spowoduje z czasem, że linki obecne na stronie stracą swoją moc (skoro strona jest nieistotna i google ma jej nieindeksować to sygnały z niej też nie mają znaczenia.)
Odnośnie paginacji to jest bardzo ciekawe: https://www.portent.com/blog/seo/pagination-tunnels-experiment-click-depth.htm – jak poziom zagłębienia wpływa na indeksację i jak ja polepszyć. Niestandardowe odkrywanie podstron tylko po to aby polepszyć indkesację i zmienić sposób zagnieżdżenia
To zależy. Być może Twoje testy poskutkowały dobrymi wynikami. U mnie zastosowanie prev/next + canonical ze stron paginacji na kategorię daje najlepsze wyniki 🙂
Zgredzie, czy mogę wiedzieć dlaczego Twoim zdaniem indeksowanie kolejnych podstron paginacji to błąd?
Poprawnie zoptymalizowana kategoria nie będzie wyświetlać duplikatu opisu na pagerach, zastosowane zostaną linki next i prev oraz zoptymalizowane będą nagłówki H1. Dlaczego wiec blokować możliwość indeksacji tych podstron robotowi? Dlaczego ma nie zaindeksowac podstron z masą np. produktów w danej kategorii.
Rozumiem, ze dajesz noindex,follow. Ale mimo to jaki jest sens blokowania indeksacji?
To nie moj artykuł ale odpowiem.
Stosuję różne metody i warianty zaleznie od skryptu i zachowania się serwisu przy stronicowaniu. Zgodnie z definicją Google powinno się indeksować całą paginację i dodać prev/next. W przypadku gdy masz opis na pierwszej stronie to na drugiej już występować nie może. Ale jeśli występuje bo skrypt tak robi to aby unikąć duplikacji wstawia się canonical na pierwszą.
Przypominam, że noindex,follow – zgodnie z tym co powiedział John – nie ma sensu. Follow zostanie zingorowane bo jest noindex.
Paweł – nie do końca. 🙂 Noindex, follow może PO JAKIMŚ CZASIE zmienić swoją rolę i znaczenie na noindex, nofollow. Po jakim czasie? Nie wiadomo. 🙂 Zobacz jak duże serwisy długo z noindexfollow żyją – i crawl rate wcale im się nie zmienia (obserwowałem logi kilku dużych serwisów).
Ale powiedz: po co FOLLOW skoro jest NOINDEX? Przeciez nie ma w indeksie. Wiem – robot i tak po niej chodzi. John wypowiadał się (nie moge znaleźc tego gdzie jak zwykle), że Noindex+Follow oraz razu jestr traktowane jako Noindex+nofollow. Tyle, że roboty po tym chodzą tak czy siak.
edit: jednak nie od razu – napisane „long term” [grudzien 2017] 🙂 dlatego nie kasuje swojej wypowiedzi. Nie mniej nadal uważam, że skoro jest noindex to po co się bawić w follow.
Im mniej błędów po stronie deweloperów tym lepiej 😉 Warto przekazać ten artykuł do działu wdrożeniowego.
Paweł – po prostu warto przyznać, że to „zależy”. 🙂
Ach no tak 😀
A co w przypadku jeżeli na drugiej i kolejnych stronach oprócz linków z atrybutami rev i next mam również link do pierwszej strony? Należy jakoś go oznaczyć?
Jeżeli masz canonical na pierwszą to nieważne co masz dalej. Zgodnie z założeniami canonical na pierwszą powoduje wyindeksowanie pozostałych podstron.
Nie rozumiem. Możesz rozwinąć, czy do tego linku który prowadzi do pierwszej strony a jest na drugiej i każdej kolejnej stronie mam dać jakiś atrybut?
Przeczytaj jeszcze raz: jeśli masz canonical na pierwszą sronę z kazdej podstrony to nie ma znaczenia co masz za atrybuty. Te strony nie będa w indeksie więc nie będą nic dawały.
Ja dodam od siebie jeszcze błąd, który popełniłem sam. Zakup szablonu WP bez sprawdzenia jak jest lekki, szybki i zoptymalizowany. Mnóstwo godzin przeznaczonych na budowę strony, aby po przejściu do etapu optymalizacji lekko się zdziwić.
Proponuję sprawdzić wtyczkę „page buildera” Oxygen Buidler. Od kilku miesięcy czy nawet już roku dostępna jest nowa 2.0 odsłona tego narzędzia. Kiedyś do tworzenia stron używałem szablonów, ale ten builder daje użytkownikowi WOLNOŚĆ 🙂 i przy tym generuje względnie czysty kod więc nie ma mowy o „divception” tak jak w przypadku innych builderów. Raz użyjesz – przestaniesz wydawać hajs na szablony! A i wspomnę że licencja kosztuje 100 dolków USD – i jest „lifetime and unlimited”.
Ostatnio zauważyłem też, że częstym błędem jest używanie java script w sposób nieodpowiedni, przez co roboty Google nie widzą treści.
Dziękuję za świetny artykuł, dzięki niemu w końcu doszedłem co jest nie tak z indeksowaniem strony przez google i to poprawiłem ! Będę wracał do tego bloga częściej !
Wszystko brzmi rozsądnie, choć co do przyjaznych adresów to nie jestem pewny czy one mają znacznie. Adres dynamiczny ?xxx oraz /xxx nie sądzę aby tworzył gorsze widoki w pozycjach strony. Mogę się mylić ale na przykładzie kilku stron ja nigdy nie zauważyłem różnicy w tej kwescji a nawet może negatywną z przyjaznym adresem gdy ktoś linkuje to wtedy automatycznie jest idealne dopasowanie treści linka i anchora co nie do końce może być dobre ale mogę się mylić. W moich obserwacjach te przyjazne url nie mają istotnego znaczenia.
Zastanów się nad swoimi komentarzami i czy na pewno rozumiesz wpisy. Adres url usunąłem. Nie spamuj.
Nagminnie spotykam się z błędnym stosowaniem nagłówków H1-H6. Nieprawidłowa kolejność, powtórzenia H1, menu jako nagłówki itd.